World Model
World-Models-Autonomous-Driving-Latest-Survey
A curated list of world model for autonmous driving. Keep updated.
📌 Introduction
✧ 世界模型用于自动驾驶场景生成相关文献整理
➢ 论文汇总
[1] https://github.com/GigaAI-research/General-World-Models-Survey 该 repo 内有目前世界模型方向的优秀论文汇总,包括基本分类:视频生成、自动驾驶和自主代理。其中自动驾驶分成端到端、以及2D、3D神经模拟器方法。世界模型的文献、 开源code、 综述。
[2] https://github.com/HaoranZhuExplorer/World-Models-Autonomous-Driving-Latest-Survey 该repo 内以‘时间’为顺序精选相关世界自动驾驶模型。且并持续更新,包括一些挑战、相关视频,包括机器人领域的世界模型使用(大多数为模仿学习强化学习方向)可参考借鉴。
[3] Awesome-World-Models-for-AD
[4] World models paper list from Shanghai AI lab
[5] Awesome-Papers-World-Models-Autonomous-Driving.
➢ 认识世界模型
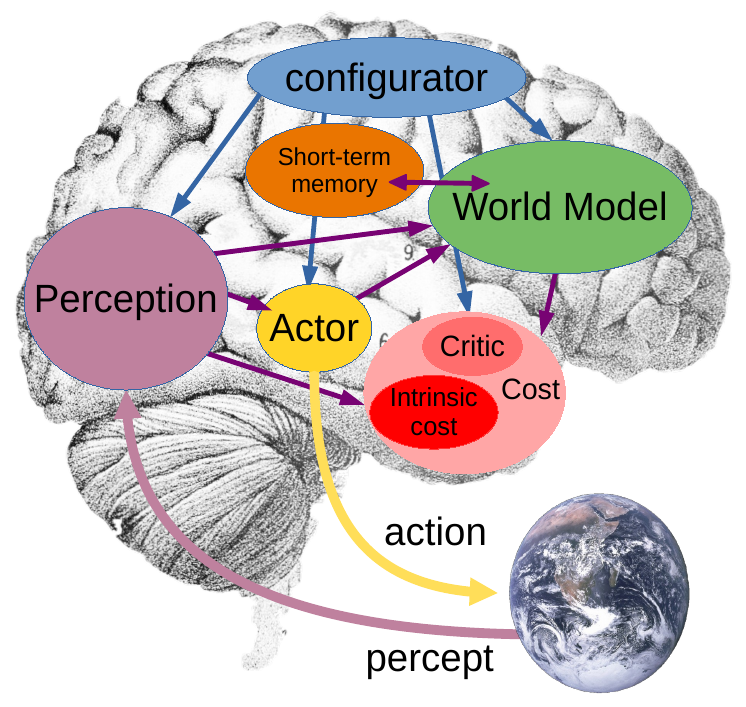
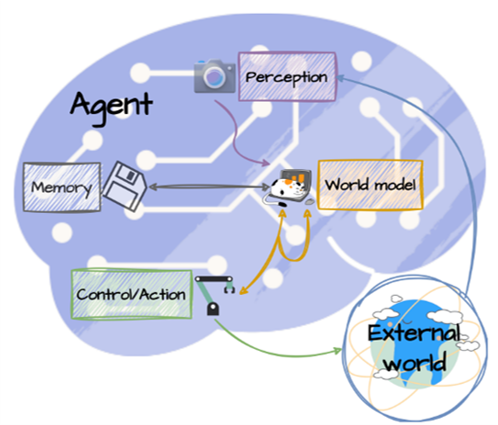
1. 简单介绍(从世界模型--> 自动驾驶世界模型用于场景生成)
[1] 世界模型简介:https://mp.weixin.qq.com/s/UmT0DjFqRPsjv2m28ySvdw世界模型是一种人工智能技术,旨在通过整合多种感知信息,如视觉、听觉和语言,利用机器学习和深度学习等方法来理解和预测现实世界。它包括感知模块、表征学习、动力学模型和生成模型,用于构建环境的内部表示,不仅能反映当前状态,还能预测未来变化。这种模型在强化学习、自动驾驶、游戏开发和机器人学等领域有广泛应用。Yann LeCun提出的这一概念,强调通过自监督学习让AI像人一样理解世界,形成内部的心理表征,以期实现通用人工智能。Meta的I-JEPA模型是基于这一愿景的实现,它通过分析和补全图像展示了对世界背景知识的应用。
[2] 影响较大的早期世界模型文章:2018年Jurgen在NeurIPS 以循环世界模型促进策略演变“Recurrent World Models Facilitate Policy Evolution”的title发表:链接: https://arxiv.org/abs/1803.10122 示例: https://worldmodels.github.io/
[3] 世界模型在自动驾驶领域的应用: https://www.bilibili.com/read/cv34465959/
[4] 世界模型用于自动驾驶场景生成以及仿真平台: https://blog.csdn.net/CV_Autobot/article/details/134002647
2.论文综述
[1] 2024-Is Sora a World Simulator? A Comprehensive Survey on General World Models and Beyond, arxiv Paper 极佳科技 (比较全面,该综述通过 260 余篇文献,对世界模型在视频生成、自动驾驶、智能体、通用机器人等领域的研究和应用进行了详尽的分析和讨论。另外,该综述还审视了当前世界模型的挑战和局限性,并展望了它们未来的发展方向。)
[2] 2024-World Models for Autonomous Driving: An Initial Survey,IEEE TIV,澳门大学,夏威夷大学。Paper(画风有趣,对自动驾驶世界模型的现状和未来进展进行了初步回顾,涵盖了它们的理论基础、实际应用以及旨在克服现有局限性的正在进行的研究工作。)
[3]2024-Data-Centric Evolution in Autonomous Driving: A Comprehensive Survey of Big Data System, Data Mining, and Closed-Loop Technologies arxiv Paper
[4]2024-Forging Vision Foundation Models for Autonomous Driving: Challenges, Methodologies, and Opportunities arxiv Paper
3.挑战赛 Workshops/Challenges
2024-1X World Model Challenge
ChallengesLink2024-ECCV Corner case Challenge
ChallengesLink2024-CVPR Workshop, Foundation Models for Autonomous Systems, Challenges, Track 4: Predictive World Model
ChallengesLink
Tutorials/Talks/
➢ 优秀团队 / 学术大佬/ 公司
■ 上海AILab(上海人工智能实验室) https://opendrivelab.com/publications/
■ 香港中文大学(陈铠老师团队)Geometric-Controllable Visual Generation: A Systematic Solution Video
■ 极佳科技(极佳科技DriveDreamer自动驾驶世界模型、WorldDreamer通用世界模型目前已成功商业化落地。)推文
■ Wayve、Tesla、旷视、中科院自动化所
■ 蔚来车企:https://www.qbitai.com/2024/07/172025.html
➢ 经典论文:(推荐加“👍”)
+ World Models are adept at representing an agent's spatio-temporal knowledge about its environment through the prediction of future changes
+ There are two main types of world models in Autonomous Driving aimed at reducing driving uncertainty, i.e., World Model as Neural Driving Simulator and World Model for End-to-end Driving
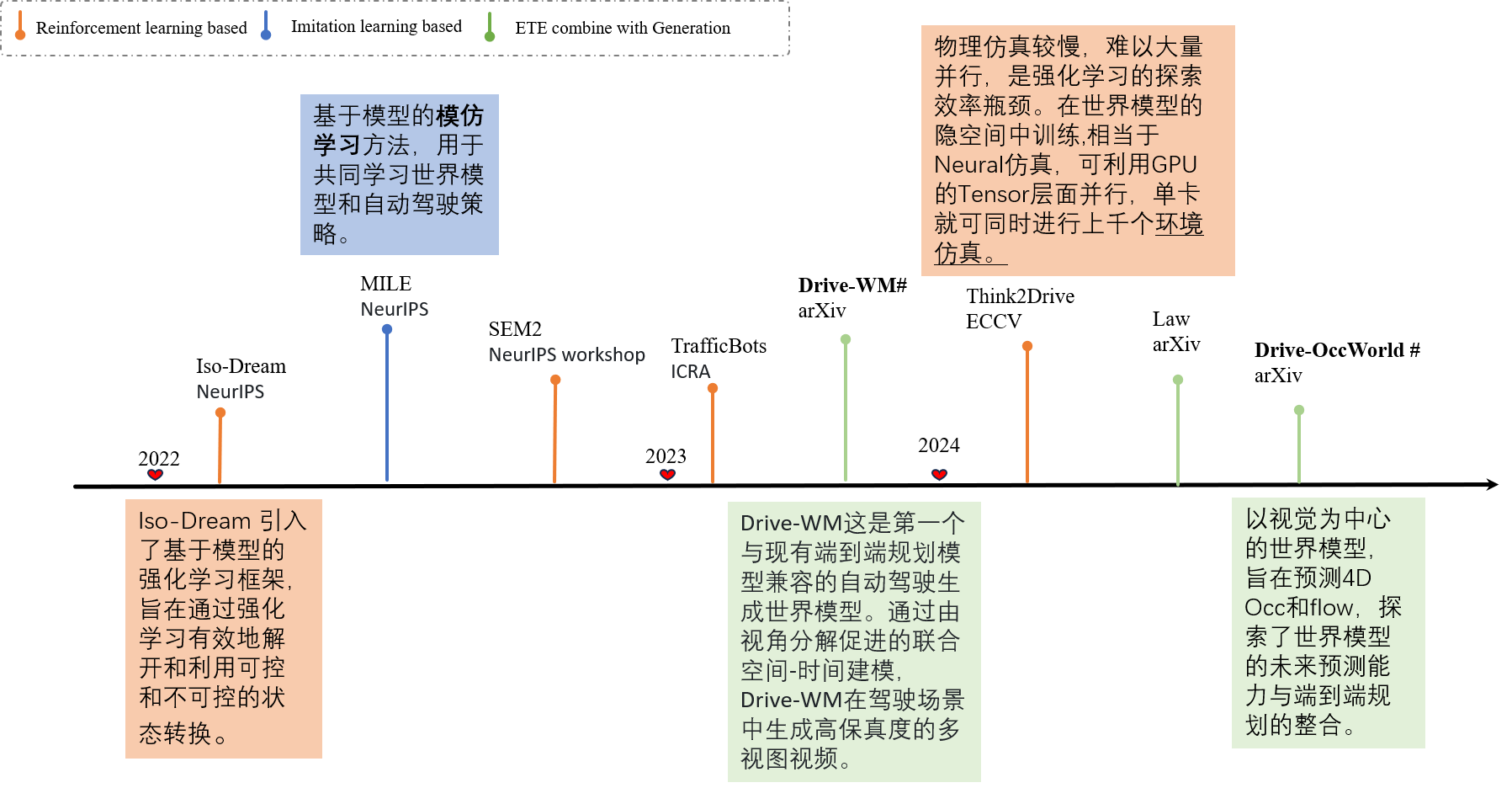
+ In the real environment, methods like GAIA-1 and Copilot4D involve utilizing generative models to construct neural simulators that produce 2D or 3D future scenes to enhance predictive capabilities
+ In the simulation environment, methods such as MILE and TrafficBots are based on reinforcement learning, enhancing their capacity for decision-making and future prediction, thereby paving the way to end-to-end autonomous driving
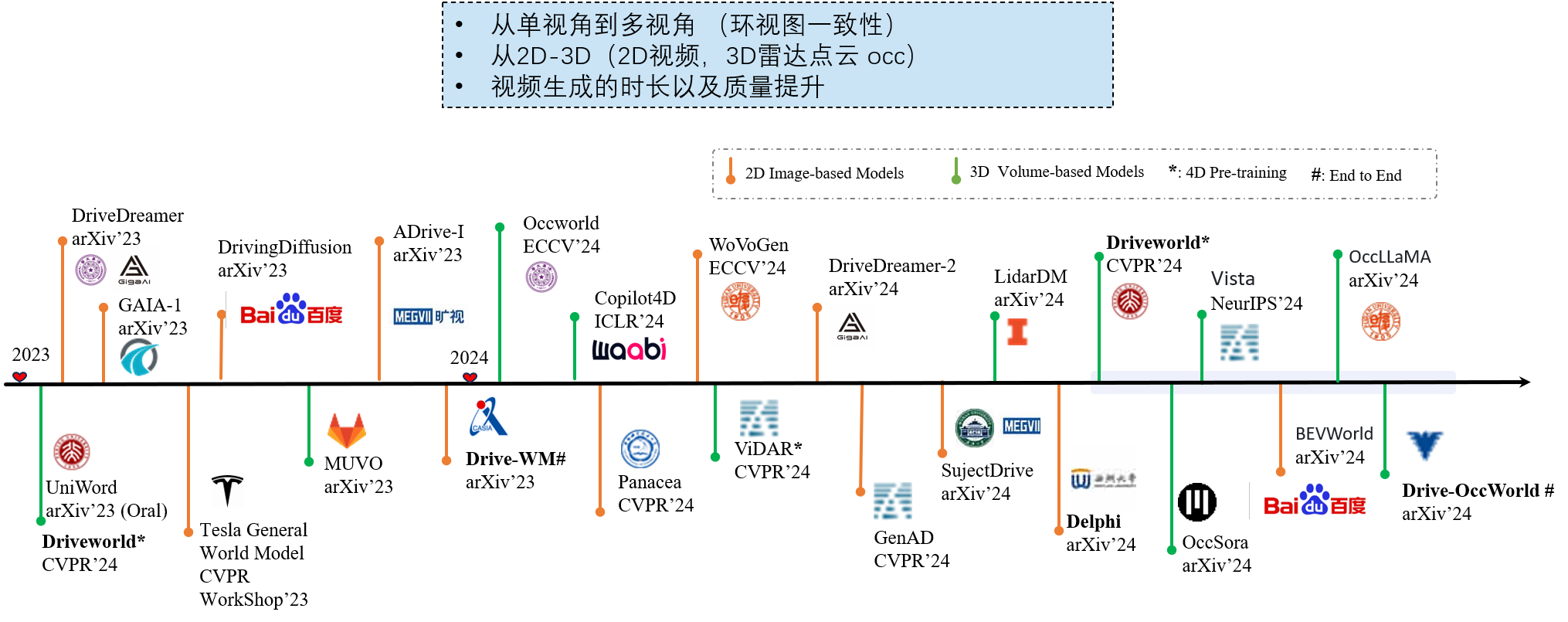
■ Neural Driving Simulator based on World Models
■ 2D Scene Generation
- (2023 CVPR 2023 workshop) [Video] (Tesla)
- 👍(2023 Arxiv) DriveDreamer: Towards Real-world-driven World Models for Autonomous Driving [Paper][Code] (GigaAI)
- (2023 Arxiv) ADriver-I: A General World Model for Autonomous Driving [Paper] (MEGVII)
- 👍(2023 Arxiv) DrivingDiffusion: Layout-Guided multi-view driving scene video generation with latent diffusion model [Paper] (Baidu)
- (2023 Arxiv) Panacea: Panoramic and Controllable Video Generation for Autonomous Driving [Paper][Code] (MEGVII)
- 👍(2024 CVPR) Drive-WM: Driving into the Future: Multiview Visual Forecasting and Planning with World Model for Autonomous Driving [Paper][Code] (CASIA)
- (2023 Arxiv) WoVoGen: World Volume-aware Diffusion for Controllable Multi-camera Driving Scene Generation [Paper] (Fudan)
- (2024 Arxiv) DriveDreamer-2: LLM-Enhanced World Models for Diverse Driving Video Generation [Paper][Code] (GigaAI)
- (2024 CVPR) GenAD: Generalized Predictive Model for Autonomous Driving [Paper][Code] (Shanghai AI Lab)
- (2024 Arxiv) SubjectDrive: Scaling Generative Data in Autonomous Driving via Subject Control [Paper] (MEGVII)
■ 3D Scene Generation
- 👍(2024 ICLR) Copilot4D:Learning unsupervised world models for autonomous driving via discrete diffusion [Paper] (Waabi)
- (2023 Arxiv) OccWorld: Learning a 3D Occupancy World Model for Autonomous Driving [Paper][Code] (THU)
- (2023 Arxiv) MUVO: A Multimodal Generative World Model for Autonomous Driving with Geometric Representations [Paper] (KIT)
- (2024 Arxiv) LidarDM: Generative LiDAR Simulation in a Generated World [Paper][Code] (MIT)
■ 4D Pre-training for Autonomous Driving
- (2024 Arxiv)-DriveDreamer4D: World Models Are Effective Data Machines for 4D Driving Scene Representation Paper
- (2024 CVPR) ViDAR: Visual Point Cloud Forecasting enables Scalable Autonomous Driving [Paper][Code] (Shanghai AI Lab)
- 👍(2024 CVPR) DriveWorld: 4D Pre-trained Scene Understanding via World Models for Autonomous Driving [Paper] (PKU)
■ End-to-end Driving based on World Models
- 👍(2022 NeurIPS) Iso-Dream: Isolating and Leveraging Noncontrollable Visual Dynamics in World Models [Paper] (SJTU)
- 👍(2022 NeurIPS) MILE: Model-Based Imitation Learning for Urban Driving [Paper][Code] (Wayve)
- (2022 NeurIPS Deep RL Workshop) SEM2: Enhance Sample Efficiency and Robustness of End-to-end Urban Autonomous Driving via Semantic Masked World Model [Paper] (HIT & THU)
- (2023 ICRA) TrafficBots: Towards World Models for Autonomous Driving Simulation and Motion Prediction [Paper] (ETH Zurich)
- (2024 Arxiv) Think2Drive: Efficient Reinforcement Learning by Thinking in Latent World Model for Quasi-Realistic Autonomous Driving (in CARLA-v2) [Paper] (SJTU)
■ 按时间顺序更新
Papers
2024-DriveDreamer4D: World Models Are Effective Data Machines for 4D Driving Scene Representation Paper
2024-DrivingDojo Dataset: Advancing Interactive and Knowledge-Enriched Driving World Model Paper
Dataset2024-Mitigating Covariate Shift in Imitation Learning for Autonomous Vehicles Using Latent Space Generative World Models Paper
Planning2024-OccLLaMA: An Occupancy-Language-Action Generative World Model for Autonomous Driving Paper
2024-Drive-OccWorld: Driving in the Occupancy World: Vision-Centric 4D Occupancy Forecasting and Planning via World Models for Autonomous Driving Paper
2024-CarFormer: Self-Driving with Learned Object-Centric Representations
ECCV 2024Paper2024-BEVWorld: A Multimodal World Model for Autonomous Driving via Unified BEV Latent Space
arxivPaper2024-Planning with Adaptive World Models for Autonomous Driving
arxiv;Planning; Paper2024-UnO: Unsupervised Occupancy Fields for Perception and Forecasting Paper
2024-LAW: Enhancing End-to-End Autonomous Driving with Latent World Model Paper
2024-OccSora: 4D Occupancy Generation Models as World Simulators for Autonomous Driving Paper, Code
2024-Delphi: Unleashing Generalization of End-to-End Autonomous Driving with Controllable Long Video Generation Paper
👍2024-Vista: A Generalizable Driving World Model with High Fidelity and Versatile Controllability
NeurIPS 2024;from Shanghai AI LabPaper2024-DriveWorld: 4D Pre-trained Scene Understanding via World Models for Autonomous Driving
CVPR 2024; __Paper,2024-UniPAD: A Universal Pre-training Paradigm for Autonomous Driving
CVPR 2024;from Shanghai AI LabPaper, Code2024-GenAD: Generalized Predictive Model for Autonomous Driving
CVPR 2024;from Shanghai AI LabPaper2024-Think2Drive: Efficient Reinforcement Learning by Thinking in Latent World Model for Quasi-Realistic Autonomous Driving
arxivPaper2024-ViDAR: Visual Point Cloud Forecasting enables Scalable Autonomous Driving
CVPR 2024;Pre-training;from Shanghai AI Lab;NuScenes datasetPaper, Code2024-Copilot4D: Learning Unsupervised World Models for Autonomous Driving via Discrete Diffusion
ICLR 2024;Future Prediction;from Waabi;NuScenes, KITTI Odemetry, Argoverse2 Lidar datasetsPaper2023-DrivingDiffusion: Layout-Guided multi-view driving scene video generation with latent diffusion model
arxiv;Generative AIPaper, Code2023-MUVO: A Multimodal Generative World Model for Autonomous Driving with Geometric Representations
arxiv;Pre-training;CARLA datasetPaper2023-Driving into the Future: Multiview Visual Forecasting and Planning with World Model for Autonomous Driving
arxiv;Generative AI, Planning;NuScenes and Waymo datasetsPaper2023-ADriver-I: A General World Model for Autonomous Driving
arxiv;Generative AI;NuScenes & one private datasetPaper2023-OccWorld: Learning a 3D Occupancy World Model for Autonomous Driving
arxiv;Occupancy Future Prediction, Planning;Occ3D dataset for Occupancy Future Prediction, NuScenes for motion planningPaper, Code2023-GAIA-1: A Generative World Model for Autonomous Driving
arxiv;Generative AI;Wayve's private dataPaperRelated papers & tutorials to understand this paper:FDM for video diffusion decoder: Paper, Code
Denoising diffusion tutorials: CVPR 2022 tutorial, class from UC Berkeley, Video
2023-DriveDreamer: Towards Real-world-driven World Models for Autonomous Driving
arxiv;Generative AI;NuScenes datasetPaper, Code (To be released soon)2023-Neural World Models for Computer Vision 'PhD Thesis';
from WayvePaper2023-UniWorld: Autonomous Driving Pre-training via World Models
arxiv;Pre-training;NuScenes datasetPaper2022-Separating the World and Ego Models for Self-Driving
ICLR 2022 workshop on Generalizable Policy Learning in the Physical World;from Yann Lecun's GroupPaper, Code2022-SEM2: Enhance Sample Efficiency and Robustness of End-to-end Urban Autonomous Driving via Semantic Masked World Model
NeurIPS 2022 Deep Reinforcement Learning Workshop;RL;CARLA datasetPaper2022-MILE: Model-Based Imitation Learning for Urban Driving
NeurIPS 2022;RL;from WayvePaper, Code2022-Iso-Dream: Isolating and Leveraging Noncontrollable Visual Dynamics in World Models
NeurIPS 2022Paper, Code2021-FIERY: Future Instance Prediction in Bird's-Eye View from Surround Monocular Cameras
ICCV 2019;Future Prediction;from Wayve;NuScenes, Lyft datasetsPaper, Code2021-Learning to drive from a world on rails
CVPR 2021 Oral;RLPaper, Project Page, Code2019-Model-Predictive Policy Learning with Uncertainty Regularization for Driving in Dense Traffic
ICLR 2019;Future Prediction;from Yann Lecun's GroupPaper, Code
Other General World Model Papers
- 2024-Hierarchical World Models as Visual Whole-Body Humanoid Controllers Paper
- 2024-Pandora: Towards General World Model with Natural Language Actions and Video States Paper
- 2024-Efficient World Models with Time-Aware and Context-Augmented Tokenization
ICML 2024 - 2024-3D-VLA: A 3D Vision-Language-Action Generative World Model
ICML 2024Paper - 2024-Newton from Archetype AI
websiteLink - 2024-MagicTime: Time-lapse Video Generation Models as Metamorphic Simulators
arxivPaper, Code - 2024-IWM: Learning and Leveraging World Models in Visual Representation Learning
arxiv,from Yann Lecun's GroupPaper - 2024-Video as the New Language for Real-World Decision Making
arxiv,DeepmindPaper - 2024-Genie: Generative Interactive Environments
DeepmindPaper, Website - 2024-Sora
OpenAI,Generative AILink, Technical Report - 2024-LWM: World Model on Million-Length Video And Language With RingAttention
arxiv;Generative AIPaper, Code - 2024-WorldDreamer: Towards General World Models for Video Generation via Predicting Masked Tokens
arxiv;Generative AIPaper - 2024-Video prediction models as rewards for reinforcement learning
NeurIPS 2024Paper, Code - 2024-V-JEPA: Revisiting Feature Prediction for Learning Visual Representations from Video
from Yann Lecun's GroupPaper, Code - 2023-Facing Off World Model Backbones: RNNs, Transformers, and S4
NeurIPS 2023Paper - 2023-I-JEPA: Self-Supervised Learning from Images with a Joint-Embedding Predictive Architecture
CVPR 2023;from Yann Lecun's GroupPaper, Code - 2023-Temporally Consistent Transformers for Video Generation
ICML 2023Paper, Code - 2023-Learning to Model the World with Language
arxivPaper, Code - 2023-Transformers are sample-efficient world models
ICLR 2023;RLPaper, Code - 2023-Gradient-based Planning with World Models
arxiv;from Yann Lecun's Group;Planning; Paper - 2023-World Models via Policy-Guided Trajectory Diffusion
arxiv;RL; Paper - 2023-DreamerV3: Mastering diverse domains through world models
arxiv;RL; Paper, Code - 2022-Daydreamer: World models for physical robot learning
CoRL 2022;RoboticsPaper, Code - 2022-Masked World Models for Visual Control
CoRL 2022;RoboticsPaper, Code - 2022-A Path Towards Autonomous Machine Intelligence
openreview;from Yann Lecun's Group;General Roadmap for World Models; Paper; Slides1, Slides2, Slides3; Videos - 2021-LEXA:Discovering and Achieving Goals via World Models
NeurIPS 2021; Paper, Website & Code - 2021-DreamerV2: Mastering Atari with Discrete World Models
ICLR 2021;RL;from Google & DeepmindPaper, Code - 2020-Dreamer: Dream to Control: Learning Behaviors by Latent Imagination
ICLR 2020Paper, Code - 2019-Learning Latent Dynamics for Planning from Pixels
ICML 2019Paper, Code - 2018-Model-Based Planning with Discrete and Continuous Actions
arxiv;RL, Planning;from Yann Lecun's Group; Paper - 2018-Recurrent world models facilitate policy evolution
NeurIPS 2018; Paper, Code
■ ➢ 发现的新的有意思的研究方向-->
生成式的World Model可以被用来当作一种仿真工具来生成仿真数据,特别是极为少见的Corner Case的数据。特别是基于Text to image 的可控条件生成Corner Case,可以进行数据增广,解决真实数据且标注少的现存问题。 然而World Model更有潜力的应用方向是World Model可能会成为像GPT一样的自动驾驶领域的基础模型,而其他自动驾驶具体任务都会围绕这个基础模型进行研发构建。 重点阅读vista 还有一篇是新出的数据集可以进行复现。
■ ➢可控条件生成-->
- ○ 可控条件生成-->magicdrive https://github.com/cure-lab/MagicDrive [paper] [Code]可作为baseline. 从几何标注中合成的数据可以帮助下游任务,如2D目标检测。因此,本文探讨了text-to-image (T2I)扩散模型在生成街景图像并惠及下游3D感知模型方面的潜力。
- ○ 可控条件生成-->magicdrive3D [paper] [Code]
- ○ 可控条件生成-->panacea https://zhuanlan.zhihu.com/p/684249231用于生成多视角且可控的驾驶场景视频,能够合成无限数量的多样化、带标注的样本,这对于自动驾驶的进步有至关重要的意义。 Panacea解决了两个关键挑战:“一致性”和“可控性”。一致性确保时间和视角的一致性,而可控性确保生成的内容与相应的标注对齐。
- ○ 可控条件生成-->drive-WM这是第一个与现有端到端规划模型兼容的自动驾驶世界模型。通过由视角[主页]分解促进的联合空间-时间建模,Drive-WM在驾驶场景中生成高保真度的多视图视频。
- ○ 可控条件生成-->Geodiffusion
- ○ -->Detdiffusion
- ○ 可控条件生成-->BevControl
- ○ 可控条件生成-->BevControl
- ○ 可控条件生成--PerLDiff
- ○ 可控条件生成学习平台--CarDreamer
- ○ 可控条件生成学习平台--DriveArena
■ ➢occ世界模型-->
- 2023-Occupancy Prediction-Guided Neural Planner for Autonomous Driving
ITSC 2023;Planning, Neural Predicted-Guided Planning;Waymo Open Motion datasetPaper
- 与occ结合的:occworld、Drive-occword、OccLLaMA、Driving in the Occupancy World: Vision-Centric 4D Occupancy Forecasting and Planning via World Models for Autonomous Driving、OccSora
1. DEFINITION
每篇文章的创新点从单一多视角到环视视角、从单一输入到多模态输入来提高生成质量。还有视频生成的时长,以及轨迹预测,基于决策的世界模型方法。需解决时空不一致性和生成场景连续性。