LLM4Anomaly
大语言模型在视频异常检测中的应用
➢ 期刊会议
https://air-discover.github.io/Hint-AD/
■ HAWK: Learning to Understand Open-World Video Anomalies
NeurIPS'24 HKUST(GZ) PaperGithub
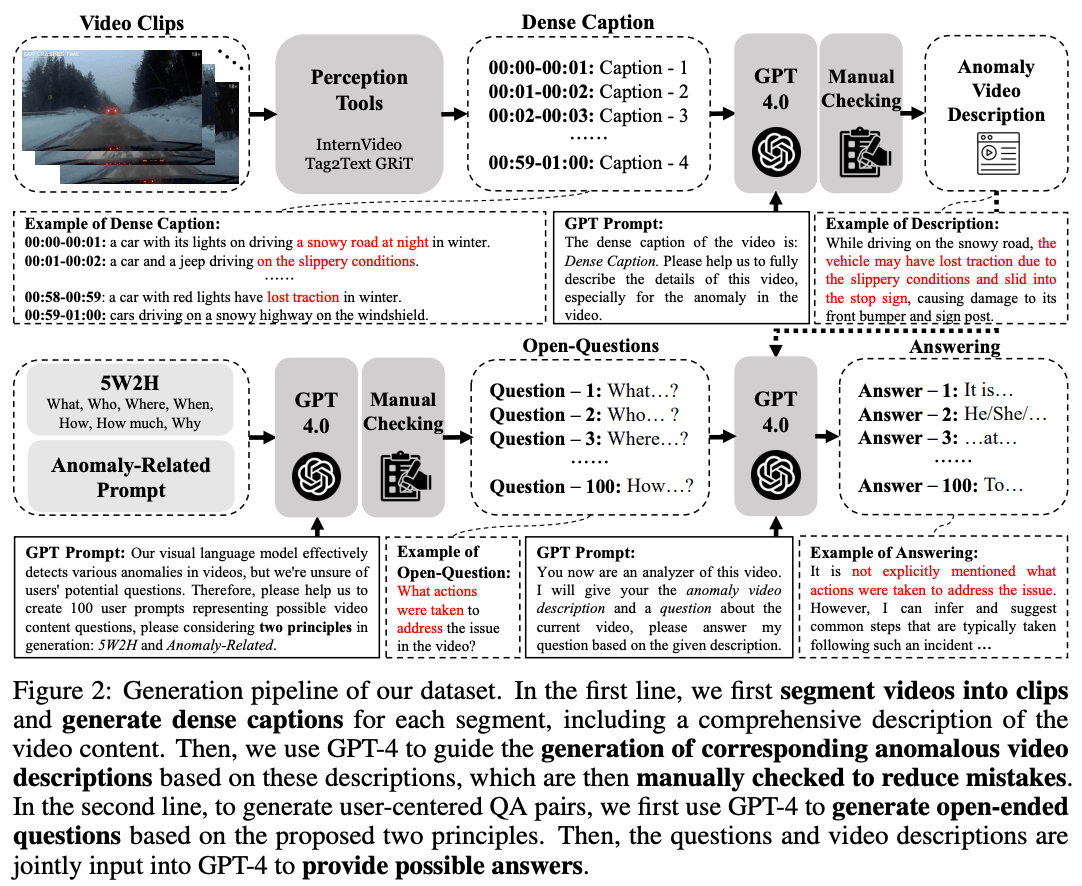
视频异常检测(Video Anomaly Detection, VAD)系统可以自主监控并识别异常,从而减少对人工操作的需求及相关成本。然而,当前的VAD系统通常受限于对场景的表面语义理解和极少的用户交互。此外,现有数据集中的数据稀缺性也限制了这些系统在开放世界场景中的适用性。在本文中,我们介绍了HAWK,这是一种新颖的框架,利用交互式的大型视觉语言模型(VLM)来精确解释视频异常。HAWK 识别出异常视频和正常视频之间运动信息的差异,明确地将运动模态整合进来,以增强异常识别能力。为强化运动关注,HAWK 在运动和视频空间内构建了一个辅助一致性损失,指导视频分支聚焦于运动模态。此外,为了改善运动到语言的解释能力,我们在运动和其语言表示之间建立了明确的监督关系。此外,我们为超过8,000个异常视频添加了语言描述标签,使其能够在多样化的开放世界场景中进行有效训练,并创建了8,000个用于用户开放世界问题的问答对。最终结果表明,HAWK在视频描述生成和问答任务中均实现了最先进(SOTA)的性能,超越了现有的基线方法。我们的代码、数据集和演示将发布在https://github.com/jqtangust/hawk。
@inproceedings{atang2024hawk,
title = {Hawk: Learning to Understand Open-World Video Anomalies},
author = {Tang, Jiaqi and Lu, Hao and Wu, Ruizheng and Xu, Xiaogang and Ma, Ke and Fang, Cheng and Guo, Bin and Lu, Jiangbo and Chen, Qifeng and Chen, Ying-Cong},
year = {2024},
booktitle = {Neural Information Processing Systems (NeurIPS)}
}
■ Uncovering What Why and How: A Comprehensive Benchmark for Causation Understanding of Video Anomaly
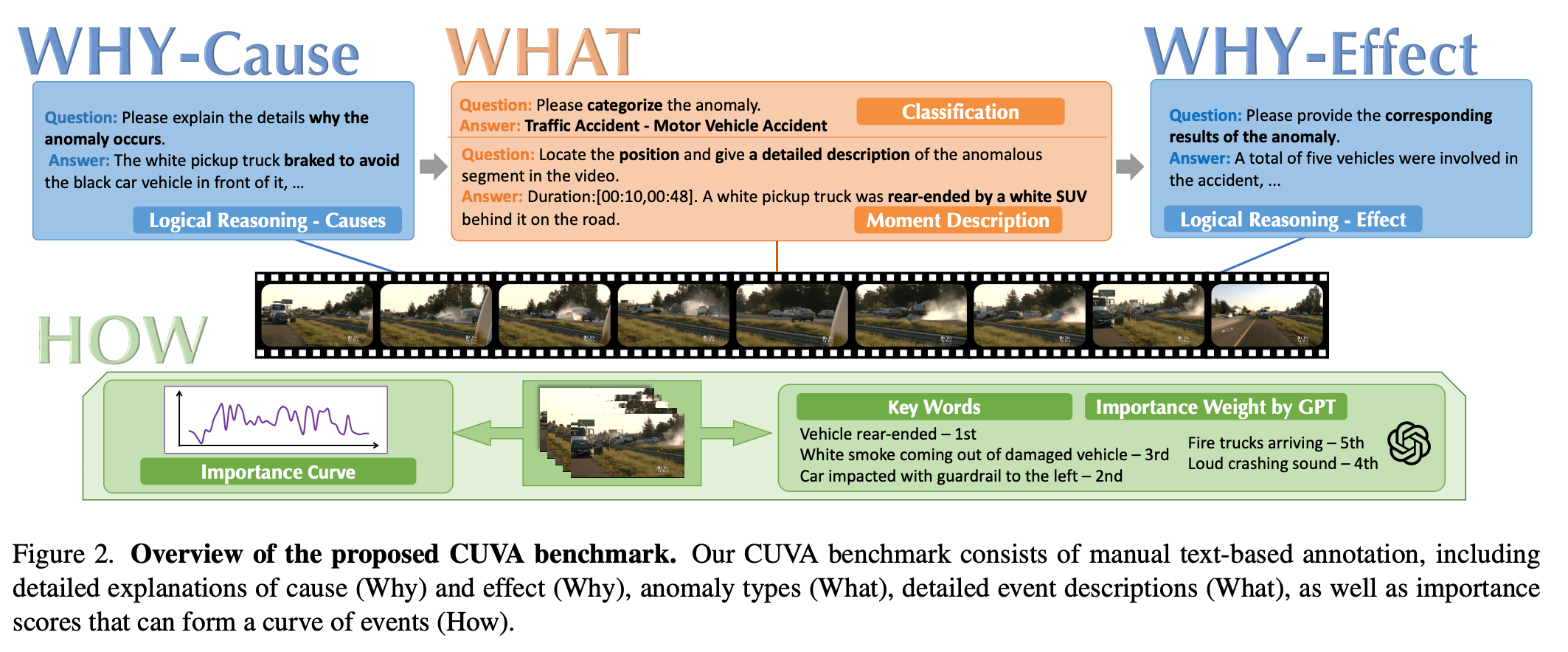
视频异常理解(Video Anomaly Understanding, VAU)旨在自动理解视频中的异常事件,从而实现如交通监控和工业制造等各种应用。尽管现有的VAU基准主要集中在异常检测和定位上,但我们更关注其实用性,因此提出了一些关键问题:“发生了什么异常?”,“为什么会发生?”,“这个异常事件的严重程度如何?”。为寻求这些问题的答案,我们提出了一个全面的用于视频异常因果理解(Causation Understanding of Video Anomaly, CUVA)的基准。具体来说,该基准的每个实例都包括三组人为标注,以指示异常的“什么”、“为什么”和“如何”,包括:1) 异常类型、开始和结束时间以及事件描述,2) 异常原因的自然语言解释,以及 3) 反映异常后果的自由文本。此外,我们还引入了 MMEval,一种旨在更好地符合人类偏好的新评估指标,用于测量现有的大语言模型(LLM)在理解视频异常的根本原因及其相应影响方面的表现。最后,我们提出了一种新颖的基于提示的方法,作为应对CUVA挑战的基线方法。我们进行了大量实验,展示了我们的评估指标和基于提示的方法的优越性。我们的代码和数据集可在 https://github.com/fesvhtr/CUVA 获得。
@inproceedings{du2024uncovering,
title={Uncovering What Why and How: A Comprehensive Benchmark for Causation Understanding of Video Anomaly},
author={Du, Hang and Zhang, Sicheng and Xie, Binzhu and Nan, Guoshun and Zhang, Jiayang and Xu, Junrui and Liu, Hangyu and Leng, Sicong and Liu, Jiangming and Fan, Hehe and others},
booktitle={Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition},
pages={18793--18803},
year={2024}
}
■ Harnessing Large Language Models for Training-free Video Anomaly Detection
CVPR'24 University of Trento PaperGithub
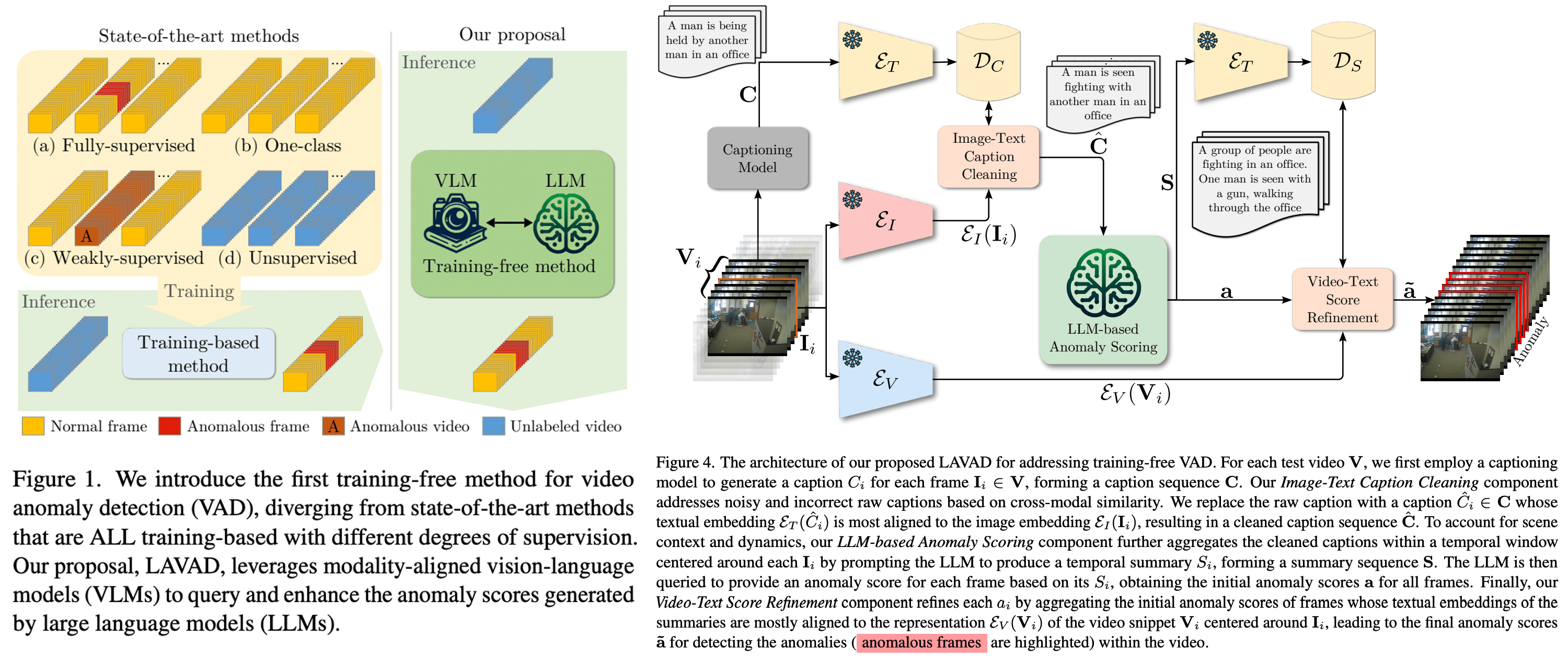
视频异常检测(Video Anomaly Detection, VAD)旨在对视频中的异常事件进行时间定位。现有的大多数工作主要依赖于通过视频级监督、单类监督或无监督设置来训练深度模型,以学习正常性的分布。然而,基于训练的方法往往具有领域特定性,这使得在实际部署中成本高昂,因为任何领域的变化都需要进行数据收集和模型训练。在本文中,我们彻底摆脱了以往的努力,提出了一种基于语言的VAD方法(LAnguage-based VAD, LAVAD),该方法通过利用预训练的大型语言模型(LLMs)和现有的视觉语言模型(VLMs),在一个新颖的、无需训练的范式下解决VAD问题。我们利用基于VLM的字幕生成模型,为任何测试视频的每一帧生成文本描述。通过文本场景描述,我们设计了一种提示机制,以解锁LLMs在时间聚合和异常评分估计方面的能力,将LLMs变成一个有效的视频异常检测器。我们进一步利用模态对齐的VLMs,并基于跨模态相似性提出了有效的技术,用于清理噪声字幕和优化基于LLM的异常评分。我们在两个大型数据集(UCF-Crime和XD-Violence)上对LAVAD进行了评估,结果显示,它在不需要任何训练或数据收集的情况下,表现优于无监督和单类方法。
■ VadCLIP: Adapting Vision-Language Models for Weakly Supervised Video Anomaly Detection
AAAI'24 Northwestern Polytechnical University (西北工业大学)
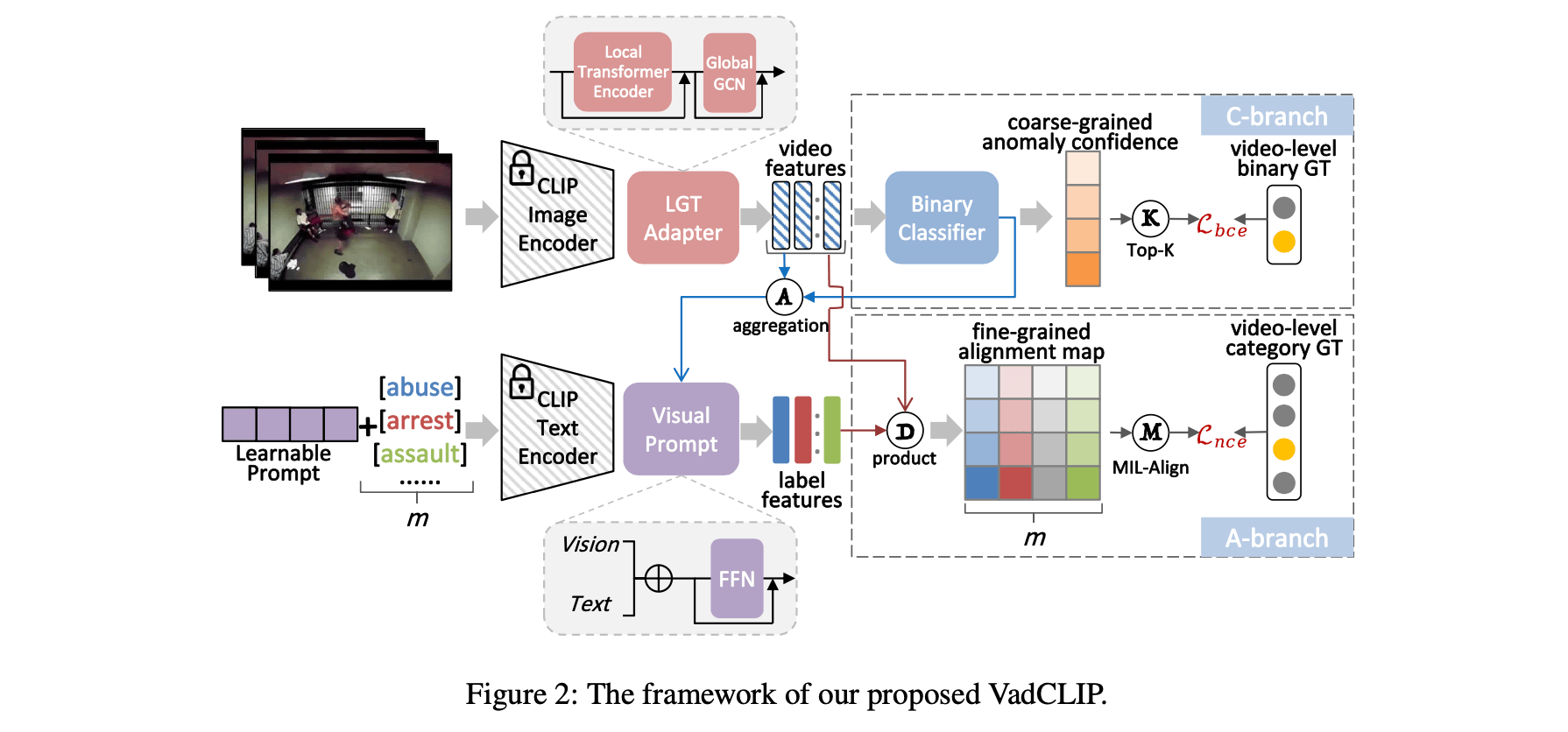
近期对比语言-图像预训练(CLIP)模型在多种图像级任务中取得了巨大成功,展示了其在学习具有丰富语义的强大视觉表征方面的卓越能力。一个开放且有价值的问题是如何将如此强大的模型高效地适应到视频领域,并设计出一个稳健的视频异常检测器。在这项工作中,我们提出了VadCLIP,一种新颖的弱监督视频异常检测(WSVAD)范式,通过直接利用冻结的CLIP模型,而无需任何预训练和微调过程。与当前直接将提取的特征输入到弱监督分类器进行帧级二分类的方法不同,VadCLIP充分利用CLIP的视觉和语言之间的细粒度关联,并涉及双分支结构。一个分支仅利用视觉特征进行粗粒度二分类,而另一个分支则充分利用细粒度的语言-图像对齐。借助双分支的优势,VadCLIP通过将CLIP的预训练知识转移到WSVAD任务,实现了粗粒度和细粒度的视频异常检测。我们在两个常用基准测试上进行了大量实验,证明VadCLIP在粗粒度和细粒度WSVAD任务上都取得了最佳性能,远超现有的最先进方法。具体而言,VadCLIP在XD-Violence和UCF-Crime数据集上的AP分别达到了84.51%和88.02%。代码和特征已发布在该网址。
■ AnomalyCLIP: Object-agnostic Prompt Learning for Zero-shot Anomaly Detection
ICLR'24 Zhejiang University (浙江大学)
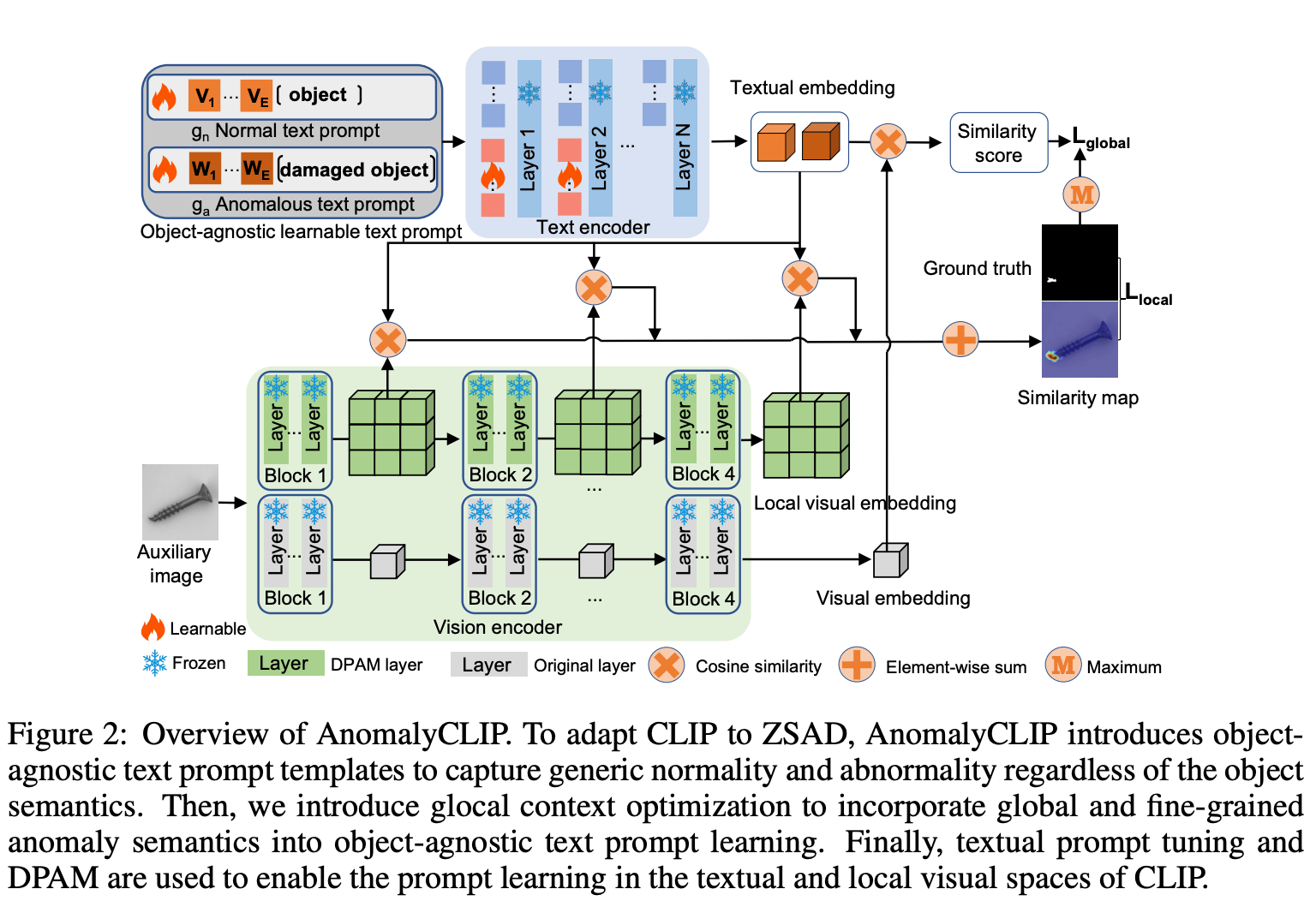
零样本异常检测(Zero-shot Anomaly Detection, ZSAD)要求检测模型在没有任何目标数据集中的训练样本的情况下,使用辅助数据进行训练,以检测异常。这在由于数据隐私等各种问题导致训练数据无法访问时尤为重要。然而,这项任务充满挑战,因为模型需要能够泛化到不同领域中的异常,这些领域中前景物体、异常区域和背景特征(例如不同产品/器官上的缺陷/肿瘤)的外观可能会有显著差异。最近,像CLIP这样的预训练大型视觉-语言模型(VLMs)在包括异常检测在内的各种视觉任务中表现出强大的零样本识别能力。然而,它们的ZSAD性能较弱,因为VLMs更多地关注于建模前景物体的类别语义,而非图像中的异常性/正常性。
在本文中,我们提出了一种新颖的方法,称为AnomalyCLIP,旨在将CLIP适配为在不同领域中进行准确的ZSAD。AnomalyCLIP的关键见解是学习对象无关的文本提示,这些提示能够捕捉图像中通用的正常性和异常性,而不依赖于其前景物体。这使我们的模型能够关注异常图像区域,而非物体语义,从而在各种类型的物体上实现泛化的正常性和异常性识别。在17个真实世界的异常检测数据集上的大规模实验表明,AnomalyCLIP在检测和分割具有高度多样化类别语义的异常方面,表现出了卓越的零样本性能,涵盖了各种缺陷检测和医学成像领域。代码将发布在 https://github.com/zqhang/AnomalyCLIP。
@inproceedings{zhou2023anomalyclip,
title={AnomalyCLIP: Object-agnostic Prompt Learning for Zero-shot Anomaly Detection},
author={Zhou, Qihang and Pang, Guansong and Tian, Yu and He, Shibo and Chen, Jiming},
booktitle={The Twelfth International Conference on Learning Representations},
year={2023}
}
■ MCANet: Multimodal Caption Aware Training-Free Video Anomaly Detection via Large Language Model
ICPR'24 National Institute of Technology, Calicut, India (印度卡利卡特国立理工学院)
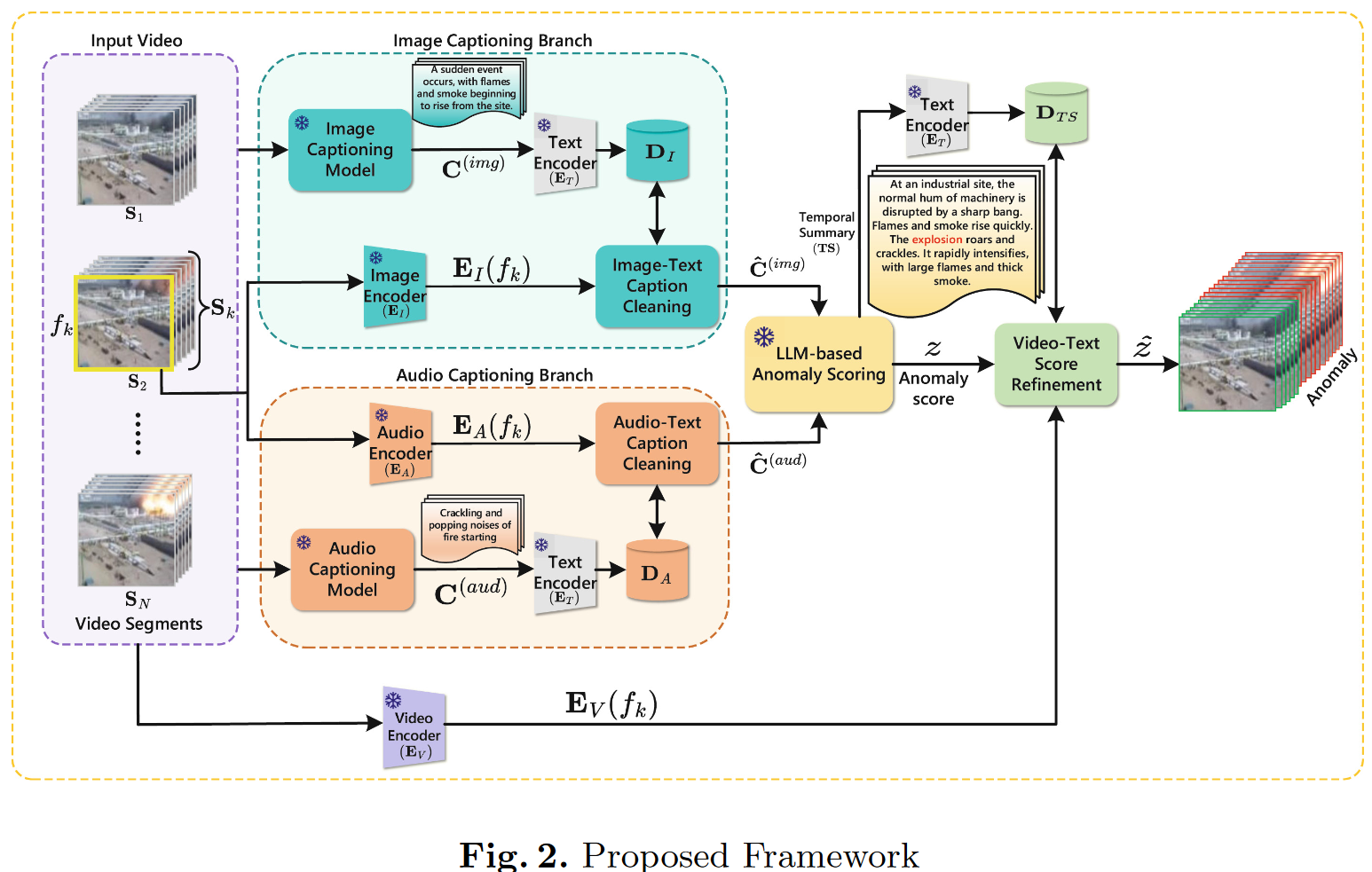
在视频异常检测(Video Anomaly Detection, VAD)方面,现有方法通常需要耗费大量精力进行数据收集和模型重新训练,这使得这些方法代价高昂且领域特定。本文提出了一种称为多模态字幕感知网络(Multimodal Caption Aware Network, MCANet)的方法,引入了一种无需领域知识的新范式来识别视频序列中的异常。这种无需训练的VAD方法通过利用现成的视觉-语言模型(Vision-Language Model, VLM)、音频-语言模型(Audio-Language Model, ALM) 和大语言模型(Large Language Model, LLM),动态生成并分析视频帧的文本描述。MCANet包含四个主要模块:第一个模块利用图像文本相似性清理由图像字幕生成模型产生的噪声字幕;第二个模块应用音频文本相似性优化音频字幕生成模型的噪声字幕;第三个模块通过LLM整合时间序列中的场景动态;最后,第四个模块基于视频文本相似性聚合语义相似帧的得分,以提升结果。为验证该方法的有效性,我们在两个大规模基准数据集(UCF-Crime 和 XD-Violence)上进行了实验。实验结果表明,MCANet在无需任何训练或数据收集的情况下,优于现有的无监督和单类方法。
@inproceedings{dev2025mcanet,
title={MCANet: Multimodal Caption Aware Training-Free Video Anomaly Detection via Large Language Model},
author={Dev, Prabhu Prasad and Hazari, Raju and Das, Pranesh},
booktitle={International Conference on Pattern Recognition},
pages={362--379},
year={2025},
organization={Springer}
}
➢ 还没中的
■ VAD-LLaMA: Video Anomaly Detection and Explanation via Large Language Models
11 Jan 2024 Singapore Management University Weakly Surpervised GithubarXiv [一作相关工作] https://github.com/ktr-hubrt/UMIL
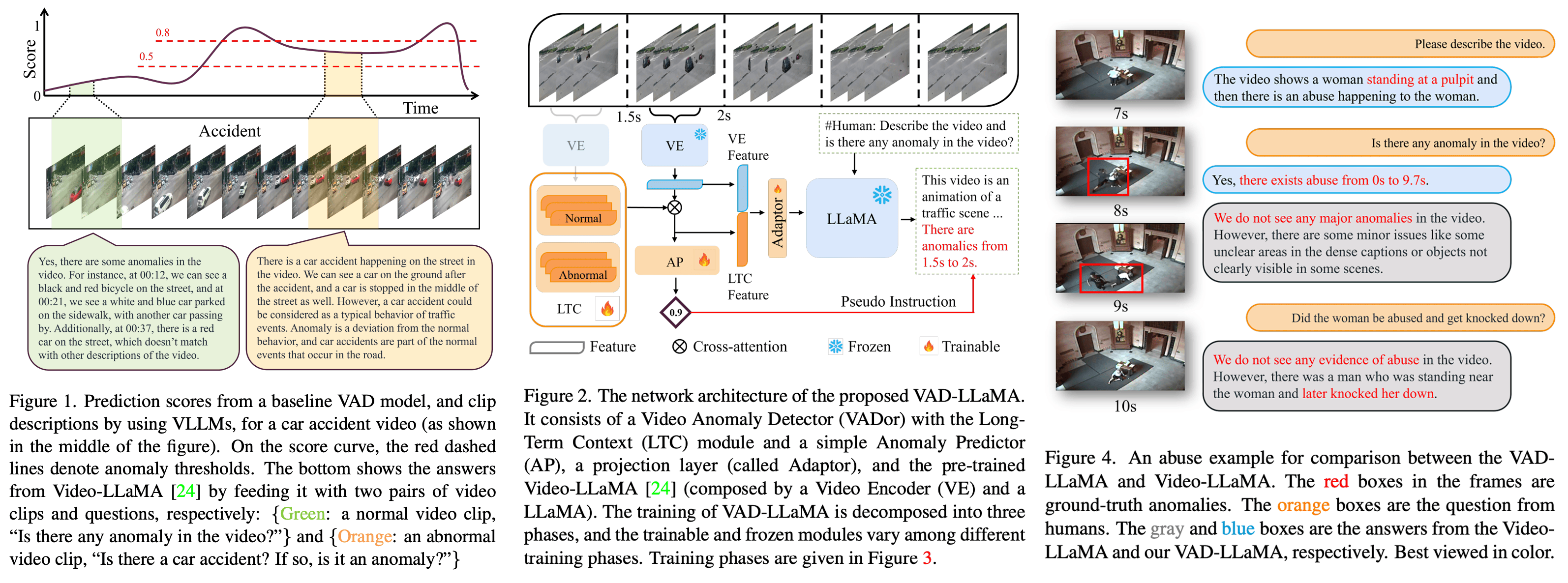
视频异常检测(Video Anomaly Detection, VAD)旨在对长时间监控视频的时间线上定位异常事件。基于异常评分的方法多年来一直占主导地位,但它们在阈值设定上的复杂性和检测结果的低可解释性方面存在问题。在本文中,我们首次将视频大语言模型(VLLMs)引入VAD框架,使VAD模型无需依赖阈值,并能够解释所检测到的异常的原因。我们引入了一种新颖的网络模块——长时上下文(Long-Term Context, LTC),以缓解VLLMs在长时上下文建模中的不足。我们设计了一个三阶段训练方法,通过显著减少VAD数据的需求和降低指令微调数据标注的成本,提高了微调VLLMs的效率。我们训练的模型在UCF-Crime和TAD基准测试的异常视频上取得了顶级性能,AUC分别提高了3.86%和4.96%。更令人印象深刻的是,我们的方法能够为检测到的异常提供文本解释。
■ VANE-Bench: Video Anomaly Evaluation Benchmark for Conversational LMMs
arXiv'24 MBZUAI arXivProjectGithub
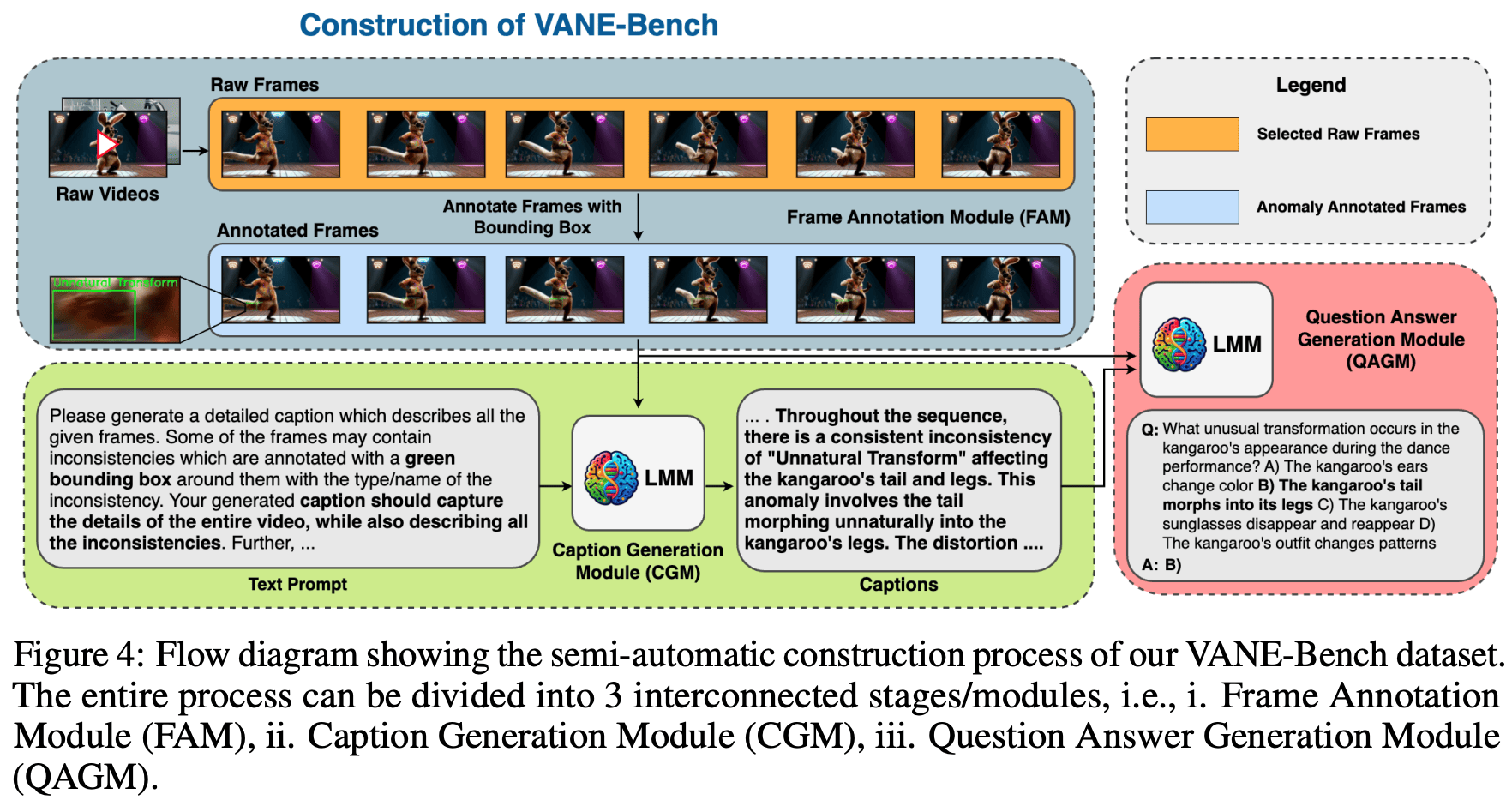
近年来,大型多模态视频模型(Video-LMMs)的发展显著提升了我们解读和分析视频数据的能力。尽管它们具有令人印象深刻的功能,当前的 Video-LMMs 尚未在异常检测任务中进行评估,而这对于其在实际场景中的部署至关重要,例如识别深度伪造、操纵视频内容、交通事故和犯罪行为等。在本文中,我们介绍了 VANE-Bench,这是一项旨在评估 Video-LMMs 在检测和定位视频中异常和不一致性的能力的基准。我们的数据集包含了一系列使用现有最先进的文本生成视频模型合成生成的视频,这些视频涵盖了各种微妙的异常和不一致性,并分为五类:不自然的变形、不自然的外观、穿透、消失和突然出现。此外,我们的基准还包含了来自现有异常检测数据集的现实样本,重点关注与犯罪相关的不规则行为、非典型的行人行为和异常事件。该任务被结构化为一个视觉问答挑战,以评估模型在视频中准确检测和定位异常的能力。我们在这一基准任务上评估了九个现有的 Video-LMMs,包括开源和闭源模型,发现大多数模型在有效识别这些微妙异常方面存在困难。总之,我们的研究为当前 Video-LMMs 在异常检测领域的能力提供了重要的见解,强调了我们工作在评估和改进这些模型以应用于现实世界中的重要性。我们的代码和数据可在 https://hananshafi.github.io/vane-benchmark/ 获取。
@misc{bharadwaj2024vanebench,
title={VANE-Bench: Video Anomaly Evaluation Benchmark for Conversational LMMs},
author={Rohit Bharadwaj and Hanan Gani and Muzammal Naseer and Fahad Shahbaz Khan and Salman Khan},
year={2024},
eprint={2406.10326},
archivePrefix={arXiv},
primaryClass={id='cs.CV' full_name='Computer Vision and Pattern Recognition' is_active=True alt_name=None in_archive='cs' is_general=False description='Covers image processing, computer vision, pattern recognition, and scene understanding. Roughly includes material in ACM Subject Classes I.2.10, I.4, and I.5.'}
}
■ Holmes-VAD: Towards Unbiased and Explainable Video Anomaly Detection via Multi-modal LLM
arXiv'24 HUST arXivGithubProject
dataset(VAD-Instruct50k)(TD)model(HolmesVAD-7B)
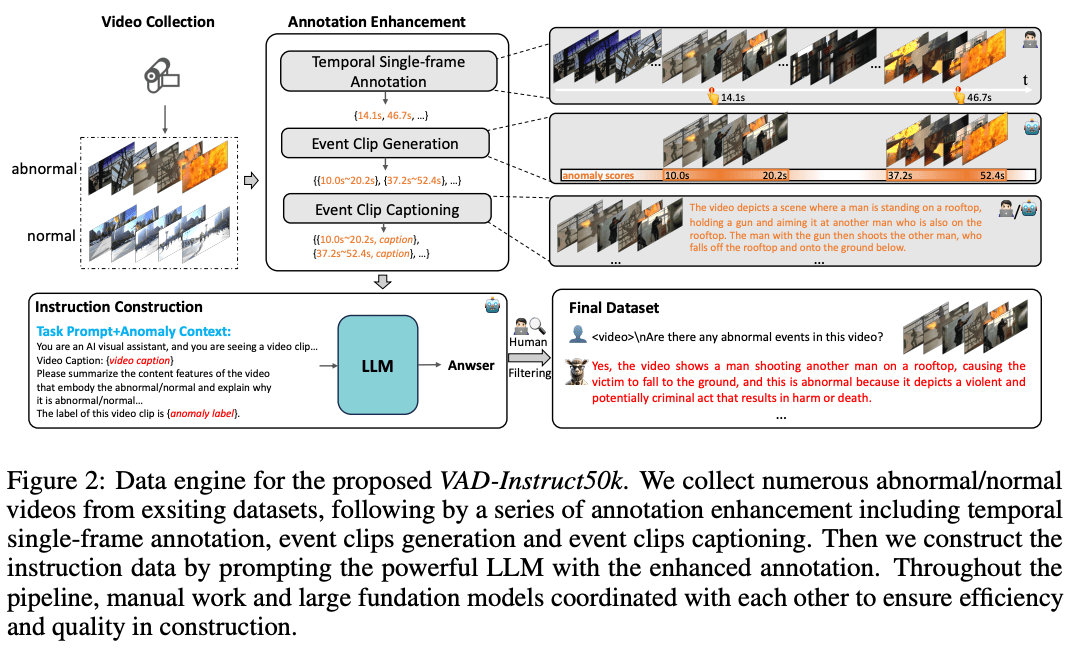
为了实现开放式的视频异常检测(Video Anomaly Detection, VAD),现有方法在面对具有挑战性或未知的事件时,往往表现出偏差的检测结果,并且缺乏可解释性。为了解决这些问题,我们提出了Holmes-VAD,这是一种利用精确的时间监督和丰富的多模态指令来实现精确异常定位和全面解释的新框架。首先,为了构建一个无偏且可解释的VAD系统,我们构建了首个大规模多模态VAD指令微调基准,即VAD-Instruct50k。该数据集是通过精心设计的半自动标注范式创建的。我们对收集的未剪辑视频应用了高效的单帧注释,然后使用稳健的现成视频字幕生成器和大型语言模型(LLM)将其合成为高质量的异常和正常视频片段分析。基于VAD-Instruct50k数据集,我们开发了一种定制化的可解释视频异常检测解决方案。我们训练了一个轻量级的时间采样器,用于选择具有高异常响应的帧,并微调了一个多模态大型语言模型(LLM)来生成解释性内容。广泛的实验结果验证了所提出的Holmes-VAD的普遍性和可解释性,确立了它作为一种新颖的现实世界视频异常分析技术。为了支持社区的发展,我们的基准和模型将公开发布,网址为:https://holmesvad.github.io/。
@article{zhang2024holmes,
title={Holmes-VAD: Towards Unbiased and Explainable Video Anomaly Detection via Multi-modal LLM},
author={Zhang, Huaxin and Xu, Xiaohao and Wang, Xiang and Zuo, Jialong and Han, Chuchu and Huang, Xiaonan and Gao, Changxin and Wang, Yuehuan and Sang, Nong},
journal={arXiv preprint arXiv:2406.12235},
year={2024}
}
➢ Open Vocabulary 异常检测
■ Open-Vocabulary Video Anomaly Detection
CVPR'24 Northwestern Polytechnical University(西北工业大学)
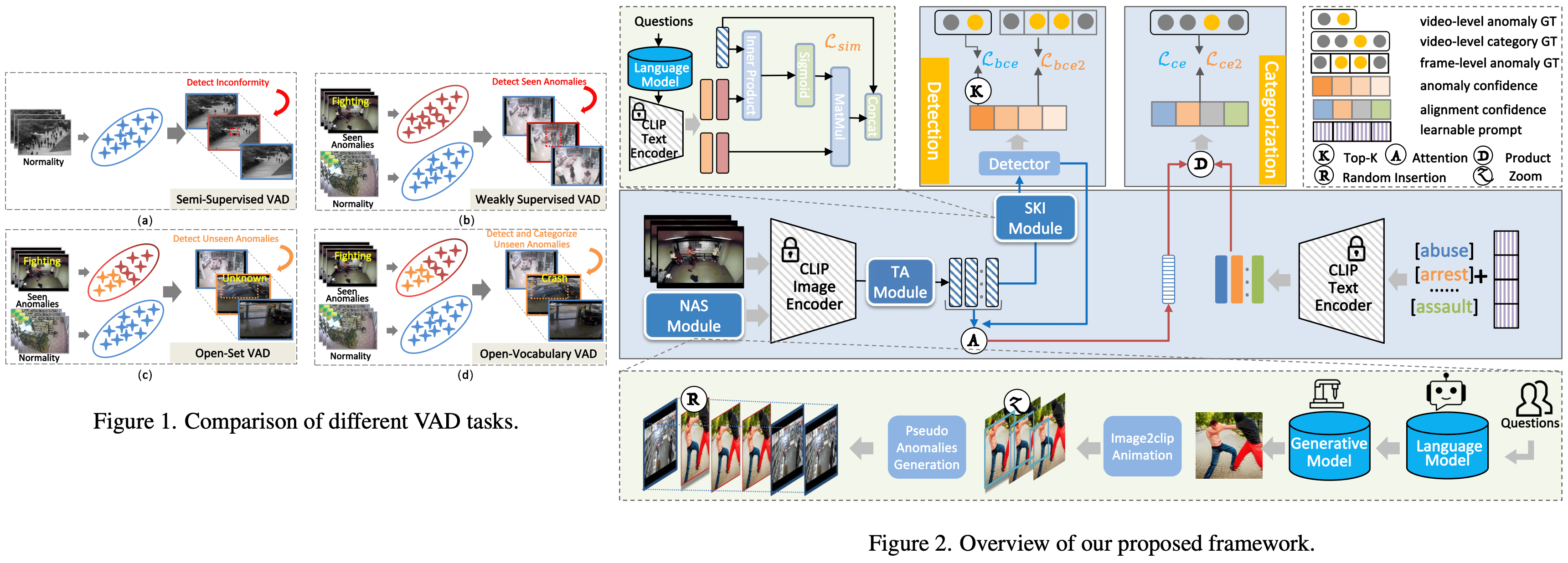
当前的视频异常检测(Video Anomaly Detection, VAD)方法在弱监督下固有地局限于封闭集设置,因此在开放世界应用中可能会遇到困难,因为在测试数据中可能会出现训练期间未见过的异常类别。最近的一些研究尝试解决一个更现实的设置,即开放集VAD,其目标是在给定已知异常和正常视频的情况下检测未见过的异常。然而,这种设置侧重于预测帧异常分数,无法识别异常的具体类别,尽管这种能力对于构建更智能的视频监控系统至关重要。本文更进一步,探索了开放词汇表视频异常检测(Open-Vocabulary Video Anomaly Detection, OVVAD),其中我们的目标是利用预训练的大型模型来检测和分类已见和未见的异常。为此,我们提出了一种将OVVAD分解为两个互补任务的模型——类别无关的检测和类别特定的分类——并联合优化这两个任务。特别地,我们设计了一个语义知识注入模块,以引入来自大型语言模型的语义知识用于检测任务,并设计了一个新颖的异常合成模块,借助大型视觉生成模型生成伪造的未见异常视频,用于分类任务。这些语义知识和合成异常显著扩展了我们模型在检测和分类各种已见和未见异常方面的能力。在三个广泛使用的基准测试上进行的大量实验表明,我们的模型在OVVAD任务上达到了最先进的性能。